Over-Subscription Cluster Resource by Opportunistic Containers
Yarn is stepping forward to improve cluster utilization. One interesting work is to provide the capability to oversell its resource for applications. In this post, I am exploring this feature and some other related ones to present a comprehensive view about how this will be done.
Motivation
One problem with yarn is that we can hardly get the cluster to reach a relative high resource utilization due to its scheduling model. Majorly because,
- Yarn containers are fixed size, once allocated, it occupies the fixed amount of resource during its entire lifecycle. However, resource usage of an application is changing over the time, it might consume very rare resource when it is idle so most of time the resource is wasted. This is even worse when there is long running services.
- Most of user sets the resource request according to the maximum required resource to ensure they get a predictable SLA for their applications. Again, most of time such configuration wastes a lot of resources.
Opportunistic containers was added in YARN-2882, as a sub-task of YARN-2877. The over-subscription work is currently work-in-progress and tracked in YARN-1011. This post is exploring how this approach improves cluster resource utilization and how it works.
Opportunistic Container
Opportunistic container is a new type of container that aims to over-subscribe system resource in order to increase resource utilization in a yarn cluster.
Guaranteed Container
Traditional container type, subscribe a fixed amount of resource from yarn cluster. Once a guaranteed container is allocated, the resource this container specified is booked from yarn capacity and yarn will ensure this amount of resource can be guaranteed at any point of time.
Opportunistic Container
The allocation decision for an opportunistic container is not depending on the capacity of the cluster, instead it is determined by the real time resource utilization in the cluster while the request is made. Which means, even the cluster capacity is all booked by guaranteed containers and there is no enough capacity to satisfy the desired requested resource of an opportunistic container, it can be still allocated as long as there is free resource available on node managers. This is also called over-subscription.
This mechanism helps to improve the utilization of the resource. However, it is necessarily to know that yarn gives no guarantee of the resources allocated to such containers. So it might be killed or preempted when it needs to recycle some resource to avoid starving guaranteed containers.
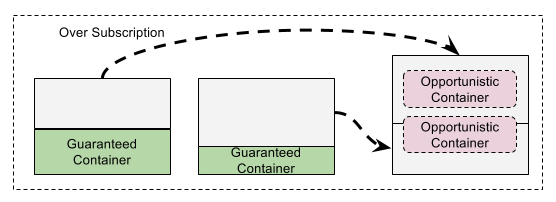
Chart 1 illustrates how the over-subscription works on a node manager. Node manager monitors the node resource usage in a certain frequency (default 3s), if it detects there is free resource available on this node, then these resource can be utilized by opportunistic containers. The total allocated the resource cannot exceed the system limit at any time.
Schedule Opportunistic Containers
Resource manager runs an application master service processor to handle the requests from application masters, it was working like following
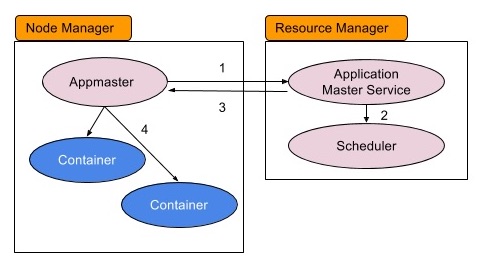
Procedure:
- Application master submits resource requests to the application master service running in the resource manager
- Application master service queries a specific scheduler to decide how to schedule containers
- Resource manager returns the scheduling decision back to application master
- Application master interpretes the allocation response and connects to specific node managers to launch containers
With adding the concept of opportunistic containers, the procedure now looks like
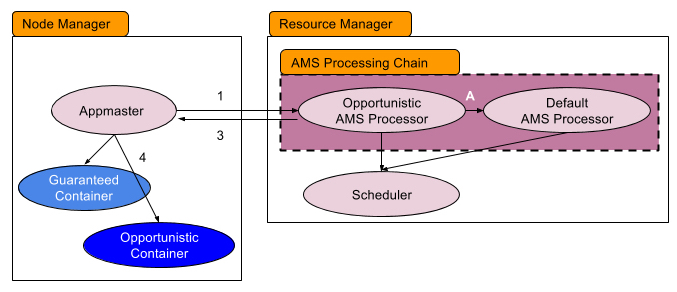
Rest of processes remain the same, except for
- There is a chain of application master service processors, the default one handles the scheduling of guaranteed containers and the opportunistic AMS processor handles the scheduling of opportunistic containers
Now let’s dive into the process how OpportunisticAMSProcessor allocates containers, specifically opportunistic containers. Unlike the default processor, its workflow generally looks like following:
- Caches all opportunistic container requests as
outstanding requests, as the queue on NMs are fixed size, so there might be outstanding opportunistic container requests cumulated over the time. - Sorts the outstanding requests in descending order by the capacity, simply it wants to serve “smaller” requests first.
NodeQueueLoadMonitorkeeps tracking of the loads of all NMs, and select top N nodes to satisfy opportunistic container requests. To determine the load of a NM, current policy is simple, eitherqueue_lengthorawait_time, which is configurable.- Distributes opportunistic containers to specified nodes and the container gets enqueued on those NMs.
- Each NM runs a
ContainerSchedulerwhich manages the lifecycle of allocated containers, including both guaranteed and opportunistic ones. On each interval, it tries to start as many as queued guaranteed containers then opportunistic containers. And it also takes care of killing opportunistic containers to make room for guaranteed ones.
A short summary, scheduling of opportunistic containers ignores checking nodes’ capacity and directly dispatches them to NMs. Their execution are started once there is few resource available, and could be preempted at anytime as long as there is new guaranteed containers arrived and found now enough resource available. In practical, when cluster utilization is high, this mechanism would cause very frequent preemptions and cause a lot of work to be wasted. There are a few key improvements need to be done,
- Pausing Opportunistic containers: It is not necessarily to kill the opportunistic container every time to make room for guaranteed ones, which is very expensive. Instead, a container can be
pausedand free up resources, once there is resource available again, it can beresumedwithout wasting previous work. This is currently working in progress YARN-5972. - Container Prompt: In some occasions, opportunistic containers need to be prompted to be guaranteed to avoid getting preempted.
The usability will be much improved with such enhancements.
Over-allocation and Preemption
Node manager over-allocation and preemption is controlled by thresholds, they are configurable percentage of nodes’ resource.
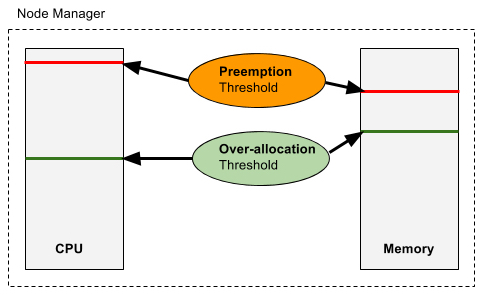
Node manager collects the memory/CPU usage by all containers from cgroups, and reports that to resource manager via heartbeat. There are two configurable thresholds, one for over-allocation and the other for preemption. When node resource utilization is under the over-allocation-threshold, this node will be scheduled with some opportunistic containers that utilizes the resource beyond this threshold and under the preemption-threshold.
If the resource usage exceeds the preemption-threshold, then node manager starts to preempt containers from this node to keep the utilization under this threshold.
Reference
[1] Opportunistic containers user doc